26 Nov 2014
This post is last from the sequence related to the internship at OpenStack as part of the Outreach Program for Woman from Gnome. I had a chance to visit OpenStack Summit in the Paris in November and here is short summary of what I saw there.
This post should have appeared a month ago, but three university projects took all the words from my head and only now I have enough time to finish it.
Read more >>>
29 Aug 2014
The internship ended a week ago, but honestly I didn’t notice it – I as contributed to OpenStack, as plan to do it later. I see it as most important outcome of the OPW program: a bunch of people will continue to help the world of free and open software.
Today I want to discuss about importance of communications and person-to-person openness, when working in such unusual configuration: remote, distributed around the world team. Only few teammates you will ever meet face to face on different conferences.
Read more >>>
18 Aug 2014
The fun project for today is to generate a sequence of plots using one gnuplot file.
The input file contains following data:
A 5
B 7
...
C 4
D 8
On the first image we want only the first record to be presented, on the second – the first two, on the last – the full dataset. The resulting sequence of images combined to GIF file looks like this:
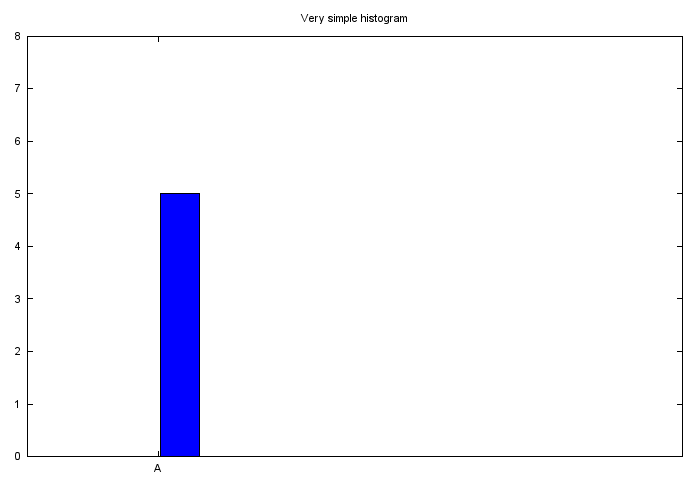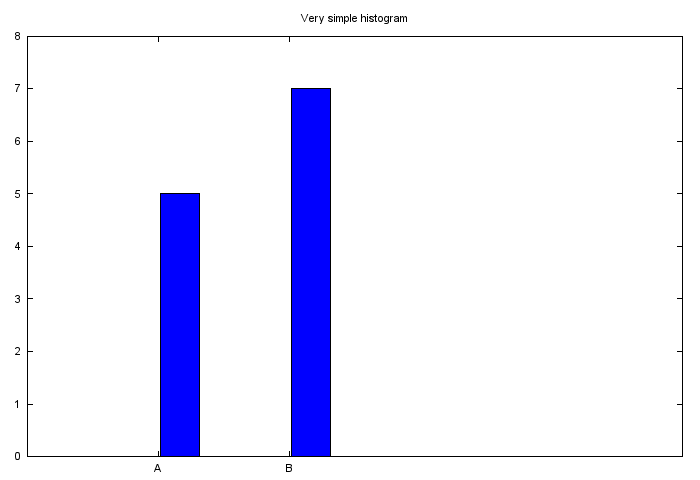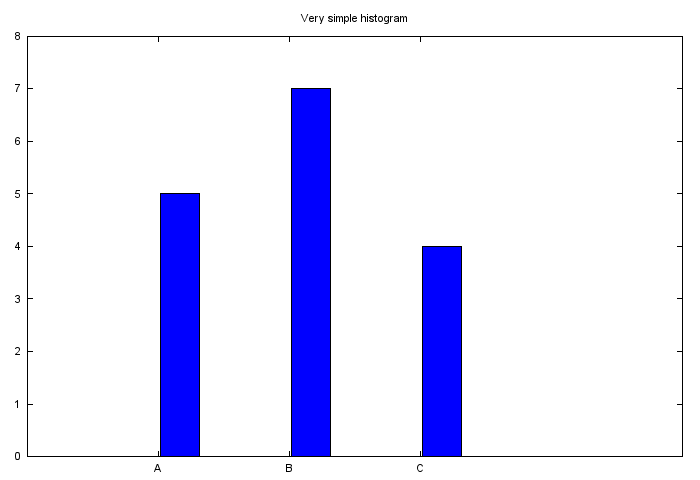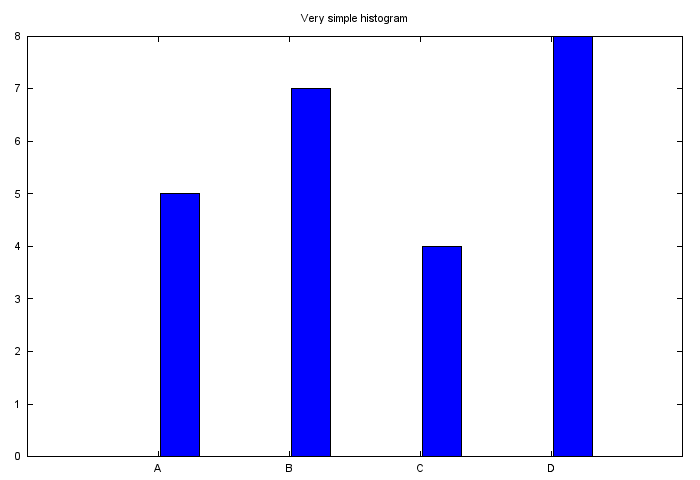
Read more >>>
16 Jul 2014
Some time ago I achieved the first and most important goal of my internship: all tests are now passing for Python 3 and the py33-gate is now voting. Since then, there were no problems with Python 3 for Marconi and hopefully it will remain so. The only missing dependency is python-memcached, that is used for caching and thus not totally blocking usage.
There were 7 commits merged in total:
with the last commit to make gate voting.
The overall impression from the work done: Python 3 is even more explicit, then Python 2.
The remaining time till August 18, I plan to spend doing several different activities:
- propose changes to other OpenStack projects to help them with Python 3 support (mostly I plan to target Oslo and Keystone).
- do something unrelated to Python 3 for OpenStack/Marconi.
- help other interns that are working on new storage and transport drivers for Marconi to make their changes Python 3 compatible.
15 Jun 2014
After several changes were merged, it is good time to talk about the overall roadmap of the process.
Marconi has good comprehensive test suite, and if it didn’t have one, then first step would be to write it. Of course having tests passing for Python 3 is not guarantee for total compatibility with Python 3 (since passing tests is not sufficient condition). But if you see failing tests, you should have very strong feeling in your stomach, that something is not working right.
Number of fixed tests is bad indicator of patch importance
On the start of internship, from all 725 tests only 123 were passing on py33, after first patch — 126, after second — 395 and so on.
Naive thought could be that first change is less important, than second. It added only 3 passing tests, whereas the second gave +169. But actually they are equally fundamental, whereas
some of the later patches, that add many passing tests, could be much more trivial.
First fix deals with problem, that sqlalchemy’s binary field accept bytes, not strings (review). Basically all tests that write to database, failed. After eliminating this problem, all other different incompatibilities became visible. One of which — the problem with decoding json from http request/response, since their bodies are also represented as bytes — was fixed in the second patch (review).
It appeared, that for 126 tests, these two problems were the only problems, and thus they become passing after second fix. But this doesn’t make second patch more or less important.
Try to fix errors by type, rather then by module
If you fix problems by type (for example, connected with strings or iterators or datetime), rather than by module (for example, fix queues, then messages, then claims etc.), you have more chances to see better solution. You see all occurrences of the problem, all corner cases and thus your solution will tend to be more general, rather than several small in-point fixes.
More you see the error in logs, earlier you should fix it
These massive errors could hide others. For example, some basic class cannot be initiated and thus all tests are failing (or that problem with any write to database giving error). Before start fixing some class of errors, you want to get as much occurrences of it as possible, so better to start fixing the one, that already has a lot of examples.
